
Intention is All You Need : NLP for the Rest of World
This is the story of a home-grown machine translation initiative working on an under-resourced language in a near-zero resource environment, equipped with the bare minimum of science but intimate knowledge of our languages and communities and the desire to perform miracles. We have big ambitions, the languages we work with count some 50 millions speakers and we believe NLP in the languages that people speak could be the key to reducing our illiteracy rate of 70% by half within 5 years. As far reaching as that goal might be, there is a larger one beyond it: full participation in the connected world, full access to the global knowledge repository in the languages people speak. To take first steps towards those goals we’ve trained dozens of Malian students in NLP, created the first Bambara-French transformer, collected text and vocal machine learning datasets, and used AI in the process of creating 180 children’s books in Malian languages. Like Ghana NLP and Keoni Mahelona & Te Hiku Media, we’re heroes, rewarded with our fleeting 15 minutes of fame.



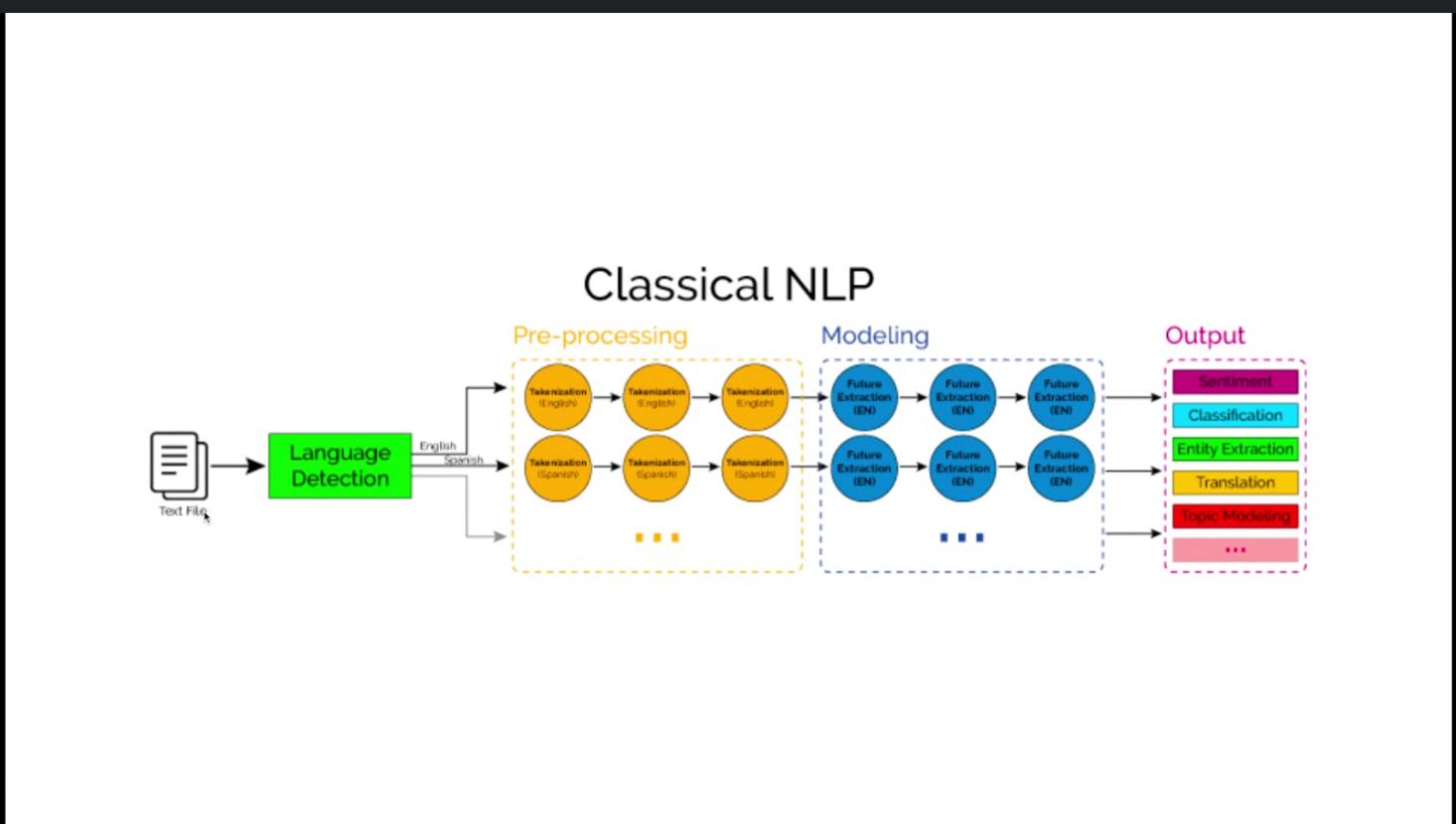



Good, but what can we really accomplish? We had not gotten very good quality out of our Bambara-French transformer when Google came out with a 32-layer, 6B parameter multilingual machine translation model that included Bambara which immediately consigned our home-grown model to the dust bin. Similar story with ASR where our home-grown effort was obsoleted by OpenAI’s multilingual Whisper model trained on 680,000 hours worth of data. Foundational work in NLP appears to be only in the reach of the very well-resourced few, we can no more contribute at this level than we could run high energy physics experiments on a supercollider. Good that the AI juggernauts are creating open foundational models and we can turn to fine-tuning, but the critical point is that the future of NLP for low-resource languages is entirely in the hands of those beneficent giants. The question imposes, while earnest and well-intentioned researchers who care about the next 1000 languages currently have corporate sanction to experiment with multilingual models, what is the priority of the full development of quality NLP for low-resource languages? In science, pathways to great things often emerge in the normal meandering course of research, but realizations always require intention. We need to form a global intention around low-resource language NLP and we need a mechanism to drive the realization of our objectives.
There is no shortage of examples of concerted activity toward specific goals on a global scale. One that seems to be particularly pertinent is the Unicode Consortium. Today, the script of every written language can be displayed in a web browser and in the vast majority of computer applications of every kind and this would have likely not been the case without the existence of the Unicode Consortium. Before Unicode, there was considerable skepticism that all the world’s writing systems could be represented by a universal character encoding standard and concerns about the cost in terms of development (virtually all widely-used software needed to be modified) and even in bandwidth and storage utilization. Fortunately, the juggernauts of the day saw the long-term interest and they, with the participation of language experts and enthusiasts worldwide, gave us the multilingual internet that exists today. NLP for world’s languages involves very different tasks than creating a system of character encodings, but many elements of the Unicode Consortium process are relevant.
The core principle of the Universal NLP Consortium might be expressed as follows : “Every language community that is willing to do the work to create the data needed to train NLP systems will have their language included in global scale NLP systems.” There are many difficulties that will have to be navigated in this declaration, but major tasks around developing guidelines, standards and commitments are clear consequences of it. Measurements of the quantity and quality of the data needed. Common tools for developing datasets, including crowd-sourcing, correction, validation, and labeling. The framework that will allow datasets to be plugged into the next wave of NLP models. Definition of what it means to have languages included in NLP systems, including measurements of quality for the variety of NLP tasks. Methods for feedback and progressive improvement of the quality of NLP systems. Coordination of language communities. Enabling exchange between language communities and providers of foundational models. Finally, imagining the global transformation that will occur when supporting the languages that people speak ends the knowledge access gap between the Global North and the Global South.
AI4D is necessarily a political as well as a scientific paradigm shift. It is pan-African, an expression of a common will to develop durable African capacity to improve the lives of Africans. Borne out of international cooperation, and focused on the use of core technologies that are not African in origin, it isn’t isolationist, but it does strongly assert that imposed barriers to the scientific advancement of Africa that can lead to social and economic development must be dismantled and access afforded to investment and resources commensurate to opportunity. AI4D is not asking, it is offering. Offering to contribute to a world where Africa is not a case apart and the benefits of AI enrich everyone in ways that matter.



