
Automatic metrics, BLUE and ChrF++, could be applied to these texts and proven widely meaningful for quick, preliminary evaluation, particularly for comparing supported languages with significant resources. However, human evaluation, on both the materials with reference translations and on other collected text samples, was used to judge fluency, fidelity to meeting and cultural appreciation. This type of evaluation provided the only meaningful feedback for the most resource-poor languages.
Table 1: Claude
Test 1: Text by Niamoye
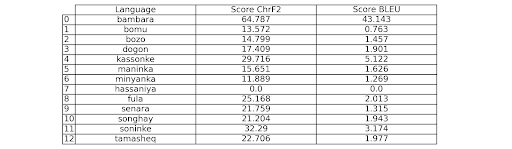
Table 2: ChrF2 and BLEU scores when translating from French into each of the languages of Mali
Box 2: Text of Mali
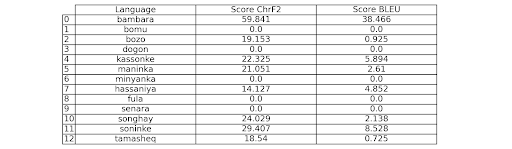
Table 3: Evaluation by experts of AMALAN and the DNENF-LN
Text of Niamoye
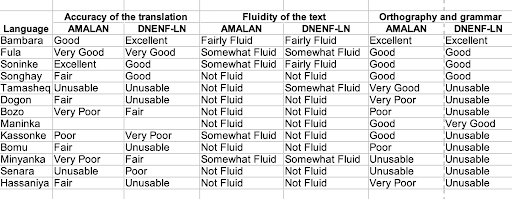
4 languages out of the 13 were considered good by human assessors, namely Bambara, Fula, Soninke and Songhay
General Summary:
The analysis seems to assess the quality of translations of texts from French into the third Malian languages, taking into account fidelity to the source text, fluidity, consistency and linguistic quality.
The reference texts were created and validated for correctness by human experts in French and all Malian languages, with the exception of Hassaniya Arabic for Niamoye. The French text was translated by Claude AI into each Malian language and ChrF2 and BLEU scores were measured against the reference translations as presented in Tables 1 and 2.
Bambara has, by a considerable margin, the highest quantitative scores (64.8, 59.8 for ChrF2 and 43.1, 38.5 for BLUE for the two texts). Kassonke, and Soninke show moderately raised scores, suggesting that Claude AI also has significant abilities in these languages.
The human evaluation of translations carried out out by the DNENF-LN and the AMALAN supported some of the results identified by automated scoring and contrasted other results. Bambara and Soninke had highly positive evaluations by both human and automated scoring, while Kassonke Fula, which from independently rated scoring seen not to be meantfully translated by Claude AI, was appreciated by the human assessors as approximately equal to Bambara and Soninke. Songhay was also evaluated much more highly by humans than its automated scores would have suggested.
There is a correspondence in the results to the quantity of digital resources available in each language. Our team has created, worked with, or is aware of significant resources in Bambara, Soninke, Fula, and Songhay, all languages for which human assessors get good marks to the automated translations. A surprise in the results is the ability of Claude AI to produce any meaningful result in languages for which there are virtually no digital resources. The relative high automated evaluation scores for Kassonke and low scores in human evaluation of meaningfulness of the text suggest a considerable ability to mimic language from very small samples without currently being able to produce intelligible text. The contrary lesson might be driven from the results with Fula, where poor self-reported scores suggest that Claude AI was able to translate the essence of the ideas covered by the text, causing it to forgo mimicry, producing a meaningful text with the vocabulary at its disposal.



